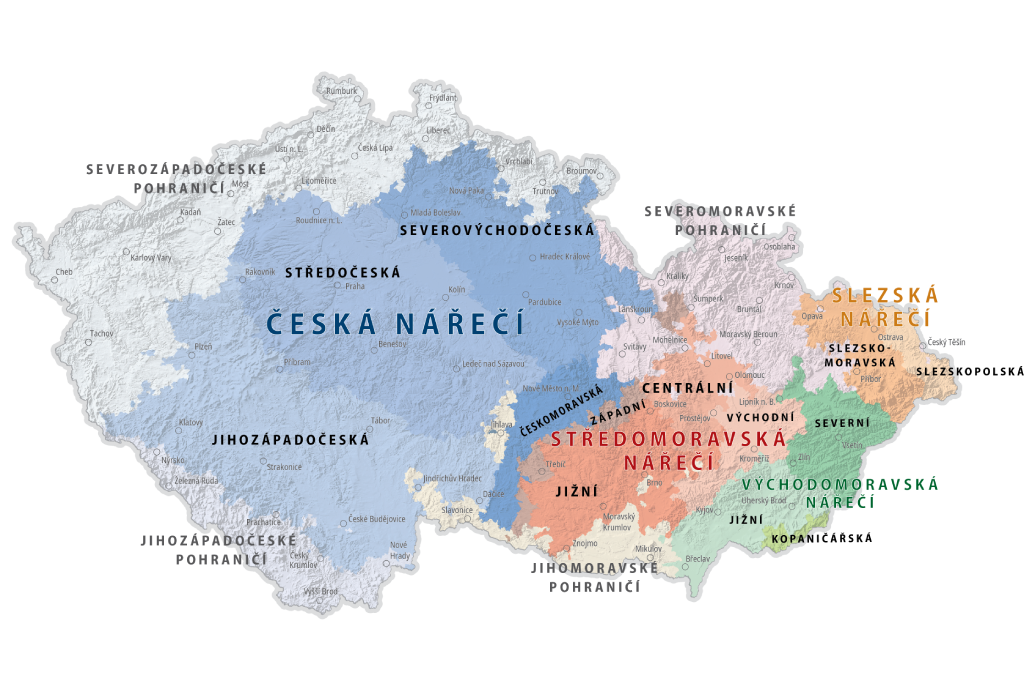
Jazyk je základním spojovacím prvkem každého národa a jeho teritoriální nářečí jsou důležitou součástí regionální identity. V moderním světě nářečí postupně mizí, jejich variabilita se zmenšuje a postupně se asimilují do jazyka představovaného mainstreamovými médii a internetem. Kvůli značným nákladům na pořizování a anotaci trénovacích jazykových dat mají nářečí prakticky nulovou podporu v moderních technologiích umělé inteligence (AI) a strojového učení (ML) reprezentovaných především automatickým rozpoznáváním řeči (ASR). V České republice se studiu nářečí věnuje dialektologické oddělení ÚJČ AV ČR, které je jediným akademickým pracovištěm systematicky se zabývajícím výzkumem nespisovných útvarů českého národního jazyka. Toto pracoviště ale postrádá jakékoliv moderní technologie pro automatické zpracování, uchování, dokumentaci a prezentaci nářečí. Výstupy dialektologického oddělení jsou navíc dostupné především odborné veřejnosti, chybí ale moderní interaktivní webové aplikace nebo služby využitelné širokou veřejností.
Projekt, který je navržený specialisty na ASR (VUT), dialektology (ÚJČ) a odborníky na interaktivní mapové zobrazování (UPOL), si klade za cíl adaptovat existující technologie a vyvinout nové postupy pro automatické zpracování, uchování, dokumentaci a prezentaci nářečí českého jazyka.
Nejprve bude zpracována podrobná metodika pro převod strukturovaných znalostí z dialektologie do strojového učení, kde je dominantní práce s daty. Stávající Archiv zvukových záznamů nářečních promluv (budovaný v ÚJČ od r. 1952 do současnosti a obsahující nahrávky s celkovou délkou záznamu přes 750 hodin) bude doplněn metadaty a bude připraven pro strojové učení. Zároveň jako prerekvizitu vyvineme software pro detekci dialektu na základě audionahrávky. Klíčovým výstupem první části projektu bude rozpoznávač řeči adaptovaný pro generování dialektologické transkripce z audionahrávek. Pro demonstraci výsledků dialektologických bádání a automatického zpracování budou vyvinuty a odborné veřejnosti zpřístupněny mapy tří nářečních diferenčních hláskových jevů s interaktivními a multimediálními prvky.
Vzhledem k blízkosti některých českých nářečí k polštině a slovenštině vyvineme multilingvální rozpoznávač zahrnující tyto jazyky pro přesné generování tzv. folklorní transkripce z audionahrávek. Ten bude využit k automatické transkripci reprezentativních nahrávek zveřejněných v plánované Databázi nářečních promluv, která bude sloužit nejen odborníkům v oblasti dialektologie a jazykovědy obecně, ale i znalcům z oboru etnologie, folkloristiky nebo historie.
Nedílnou součástí projektu bude služba veřejnosti: Jazyková paměť regionů České republiky bude interaktivní mapová aplikace naplněná existujícími nářečními daty (s respektováním pravidel zveřejnění dat), dostupná široké veřejnosti nejen pro zobrazování, ale i pro komunitní plnění audiovizuálním obsahem, např. záznamem prarodičů mluvících nářečím. Ambicí této aplikace je pozvednout zájem o uchování a rozvíjení českých nářečí coby objektu regionální hrdosti, využití v odborném i obecném školství a zvýšení jejich atraktivity pro aplikace umělé inteligence. Nedílnou součástí projektu po celou dobu jeho trvání jsou sběry nářečních dat ve vybraných regionech a jejich manuální i automatické zpracování. Hlavním publikačním výstupem projektu bude kniha Nářečí českého jazyka dříve a nyní, doplněná řadou článků a konferenčních příspěvků jazykovědného i technického zaměření.